Archive for the ‘Uncategorized’ Category
I2C 20×4 LCD module and Arduino
Recently I was working on a ZigBee project using XBee. Since XBee occupied the Arduino UART port, I decided use a character LCD for debug logs. I got the SainSmart 20×4 LCD module with i2c interface. The connections are simple:
| Arduino | LCD |
|---|---|
| 5v | VCC |
| GND | GND |
| SDA | A5/SDA |
| SCL | A4/SCL |
But I couldnt make it work with sample code provided, after few googling I found that the sample code has a wrong i2c address. Even after using the correct I2C address(0x3f), it didnt work, but I was getting only to horizontal black bars on the screen.
I confirmed the I2C is working by using I2C Explorer. Finally after updating the i2c library and with the following code, it started working. I found this code on a amazon review and modified for my purpose.

Fix loop in a linked list
Cycle or loop in a linked list with  nodes is shown in pictorial representation.
nodes is shown in pictorial representation.

Loop in a singly linked list
In this picture the number of nodes in the list is and the last node points to node at a position x(which created the cycle). From the picture it is obvious that to fix the loop:
- Find the last element
- Correct it to point end(NULL)
In the above steps, step 1(find the last element) is little difficult if total number of nodes in the list is unknown. In this post I will describe a method I discovered to find the last node. I drew couple of pictures to explain the complexity of the problem. The following pictures explains the same loop condition but in different form. It explains why it is hard to find the last node.

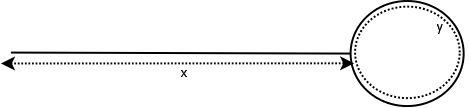
The illustration also tells us the following

where
is total number of nodes in the list
 is number of nodes before the cycle starts.
is number of nodes before the cycle starts.
 is number of nodes forming the cycle.
is number of nodes forming the cycle.
If we have value of and then the equation can be solved, which will give the last node’s location.
Finding
- Detect the cycle using Floyd’s Cycle detection algorithm. (Two pointer with varying speed)
- When cycle is detected
- Store the current node as H
- Move to next node and increment y(y++)
- If current node is H then exit
- Goto step 2
Finding
Let’s first see the easiest way to solve this:
- Have two pointers (p1, p2)
- p1 = node 0
- p2 = p1 + y nodes
- if p1 == p2 then we found the result is

- p1 = p1 + y nodes
- goto step 3.
The complexity of this algorithm linear depends on . For example if is 10K and is 2 then number of node visits are > 20K. In other words the complexity is  .
.
I believe it can be done in  or
or  with following method This following diagram captures state when the “tortoise and the hare” algorithm detects the cycle.
with following method This following diagram captures state when the “tortoise and the hare” algorithm detects the cycle.
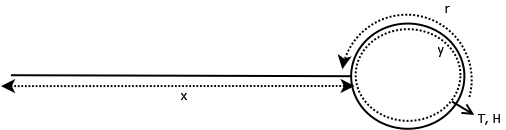
Lets define few more variables at the time of cycle detection:
 is the total number of nodes tortoise traveled.
is the total number of nodes tortoise traveled.
 is the total number of nodes hare traveled.
is the total number of nodes hare traveled.
 can be defined as number of nodes before the ‘last node’
can be defined as number of nodes before the ‘last node’

where c is the number of complete cycles hare covered.

From this we can derive

Using value of  , can be derived.
, can be derived.

Using this formula can be found. With this value, the last node can be found by travelling  nodes where T and H met.
nodes where T and H met.
Kernel(FreeBSD) Concurrency
- Interrupt disabling
- Spinlock
- System priority level
- Mutex
- Exceptions
- Faults
- NMI
- Locking order heierarchy should be maintained to avoid dead locks.
- Fine grained locks instead of single big lock to gain performance on SMP.
- And all spinlocks are at greater SPL than scheduler.
- All spinlocks should have a associated SPL and at that or greater SPL level only the spinlock should be taken.
- In simpler term spl is equivalent to masking interrupts.
- SPL is per processor, so the spinlock should have locking order hierarchy, otherwise deadlock for sure.
- Mutex cant be used in certain situations eg: a interrupt handler which runs without context cant take mutex because it might be put into sleep.
- Combining mutex and spinlock requires only one condition – after a spinlock is taken no mutex acquire should be attempted.
Better build system
I was using “make”(http://en.wikipedia.org/wiki/GNU_build_system) to build and clean my projects. The makefiles grew bigger enough to not maintainable state. Recently I came to know about waf(http://code.google.com/p/waf/) from a forum, so decided to give a try. I went through the waf documentation and it took 2 hours to understand how it works and it took 2 days to convert all my makefiles to waf wscripts and wscript_build files.
The basic problem with make was I have write rules to how to build object files from source and
 then to clean I have to write how to delete the object files. With waf the problem is simplified, you have to tell what all source files and it will take care of how to compile and link. It will also take care of how to clean the project and the dependency between files are also taken care, so no need for gcc –M and dependency files etc. The feature I liked in waf is it has colored output with progress bar 🙂
then to clean I have to write how to delete the object files. With waf the problem is simplified, you have to tell what all source files and it will take care of how to compile and link. It will also take care of how to clean the project and the dependency between files are also taken care, so no need for gcc –M and dependency files etc. The feature I liked in waf is it has colored output with progress bar 🙂
The other problem solved in Ace project compilation was build configuration. Waf will configure the project for the first time, so it solved the different cross compiler required for Ace OS.
Waf(http://code.google.com/p/waf/) is really good alternative/replacement for make tools.